
Our testing has shown that for small data sets the difference in storage requirements between a UUIDNumber and a UUID is negligible.
Relational data schemes are based on having a unique identifier. The fact that every record a unique ID allows us to specify an exact relationship between one record and another. With this in mind, we expect to find a field ID in every table because they are necessary.
Because we must use ID fields in our databases, we have some interest in what is the best way to use them. In this article, we are going to discuss using UUIDs and we’ll look at the associated costs and benefits associated with them.
What do we prefer: speed or space?
We know that FileMaker has fast operations for small data sets but when it is put under load, does your database slow to a crawl or does it continue to perform well? Using number fields for IDs is reported to produce faster results for related processes on large data sets. If you are handling large data then you’d prefer to have the fastest operations possible.
Another consideration is space. If you expect your tables to store large numbers of records then you may want to conserve space. By this reckoning, a UUIDNumber is 50% larger than a UUID. The actual difference for each ID may only be 8 bytes, but that can become important when dealing with many thousands or millions of records. Large data sets already occupy a lot of space, so you don’t want to carry extra baggage unless it is absolutely necessary.
It appears that we have to make a choice between speed and space.
We do have a Choice
FileMaker provides a two functions to generate universally unique IDs: Get(UUID) and Get(UUIDNumber). Both of these functions will generate an ID which is theoretically unique which makes them an ideal option for IDs. 1
Get(UUID) returns a unique 16-byte (128-bit) string, e.g., E47E7AE0-5CF0-FF45-B3AD-C12B3E765CD5
Get(UUIDNumber) returns a unique, 24-byte (192-bit) number, e.g., 3351455178917488228606469712264530601969081773070792730006
Calculating the data size for the raw data will give us an indication for the amount of space we need for either type of ID. 65,536 UUIDs can be stored in a megabyte whereas we can only store 43690 UUIDNumbers in a megabyte. On that basis, you could conclude that UUIDs will be space efficient in comparison to UUIDNumbers. However, the raw storage is only a part of the story. The more important measure is how much storage is required when they are stored in a FileMaker database.
FileMaker allows you to store your UUID as a number or as text. The internal storage mechanisms will influence the total size required, so we need to look at how a database actually behaves under different scenarios.
Stepping Back
Prior to FileMaker v12 when the Get(UUID) function was introduced the easiest way to generate a unique number within a table was to use the serial number options.

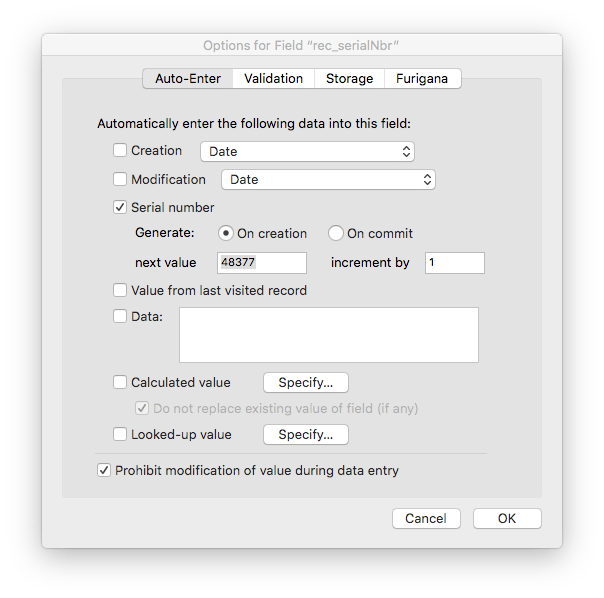
A feature of a good ID is that it is unique. Serial numbers are still an option for generating a sequence of numbers. There are caveats around their use as IDs, which are concerned with the fact that small integers are extremely common. This leads to the possibility of ID collisions when data is manipulated in a table. Data collisions sounds mundane, but nobody wants to deal with the mess that can result. In response to requests from developers, FileMaker introduced the Get(UUID) function in v12 and later in v17 it introduced Get(UUIDNumber). These UUID functions allow us to avoid ID collisions.
The UUID function introduced in v12 can generate up to 2122 unique strings. That is roughly 5.3 million, million, million, million, million, million. The UUIDNumber generates a considerably larger number, around 2186 unique strings. That is 18.4 million, million, million times larger than 2122.
Choosing your Field Type and looking at Settings
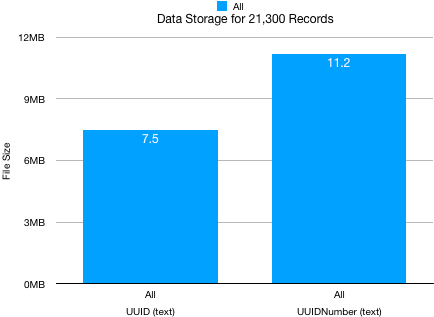
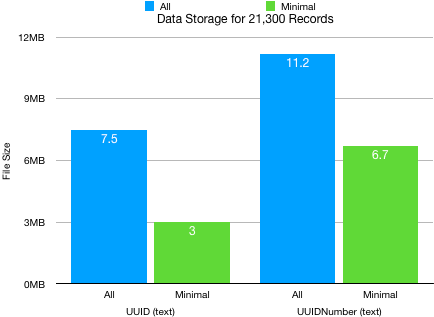
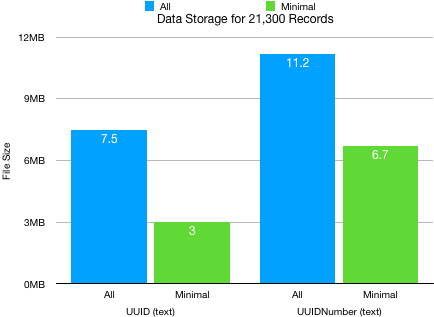
The price of this uniqueness is storage space. Let’s look at what is needed. Get(UUID) generates a 128 bit hexadecimal string, it is text and requires a text field. We can compare the storage requirements of Get(UUID) and Get(UUIDNumber) when they are placed into a text field. We can see from the graph that the storage requirements for the two UUID types reflect our common sense, the longer strings of UUIDNumber require more space.


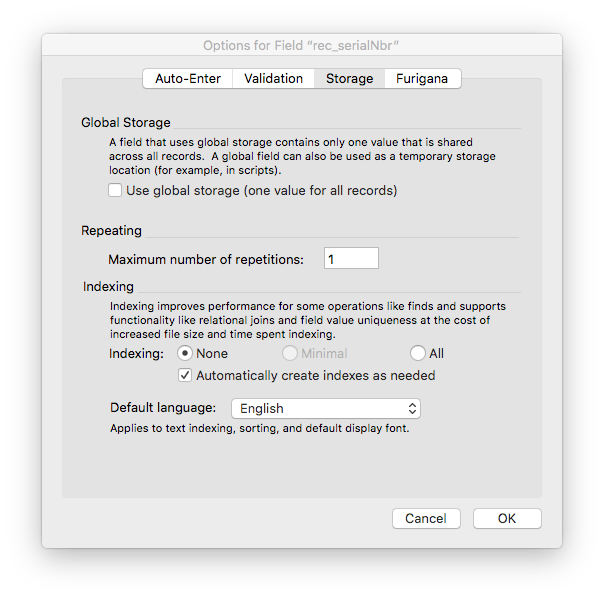
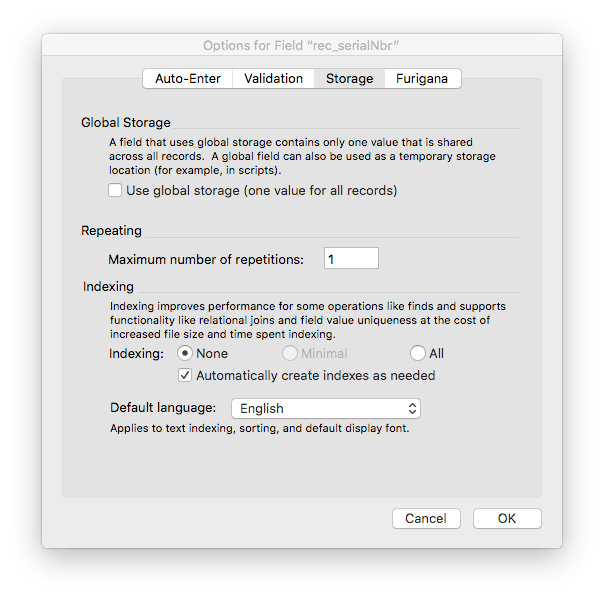
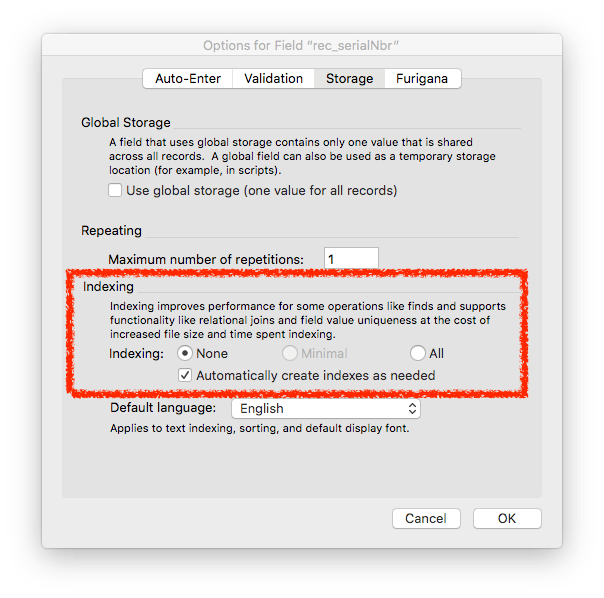
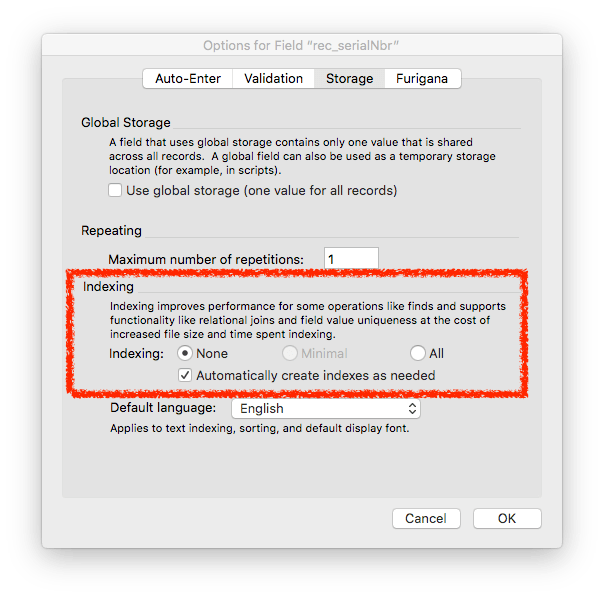
Text fields have indexing options which by default are set to “none.” However, the secondary option “Automatically create indexes as needed” is checked by default. You can see that below. This is a convenience setting that makes good sense for fields that are being used for natural language data.
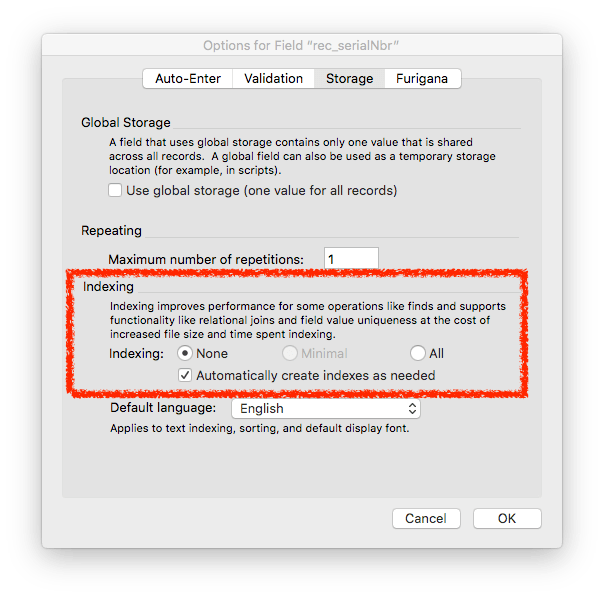
However, this convenience setting creates an issue for fields being used for IDs because they have to be indexed to be used in a relationship. The issue is not really that the indexes will be automatically created. The issue, for our discussion of storage, is that the default setting allows two types of indexing and this affects the amount of space required. Look at the difference is requirements between Minimal indexing and All Indexes.

We can see several things in this graph. This first thing that we can see is that the settings you use for your ID fields can cause large differences in the storage requirements. At 21,300 records the least optimal setting requires between three and four times as much storage space.
When creating ID fields you should take control of the field indexing settings yourself.
The automatic indexing used by FileMaker is sensible. It begins by creating the minimal indexes and only creates all indexes when it is necessary. However, it will use it’s own rules to decide when to create the extra indexes. This can cause surprises when the database size swells suddenly. If you specify that your ID fields should be indexed and (for text fields) should only use minimal indexing you will ensure that your database isn’t being bloated unnecessarily.
Another thing that we can see is that the ratio of All and Minimal indexes is different. When all indexes are ON the difference is very similar to the difference in the string lengths. The UUIDNumber is about 50% longer, so things look simple. That changes when we switch to minimal indexes. The storage for UUIDNumber is more than double, so there is something going on behind the scenes which is not obvious to us.
What about using a Number field for UUIDNumber?
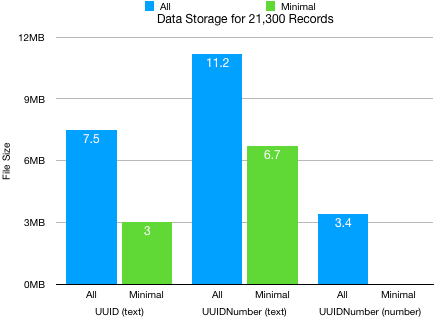
So far we’ve been looking at the storage requirements for text fields. What happens when we switch to using number fields to store UUIDNumbers?
When we use number fields for UUIDNumbers we get under-the-hood optimisations for the data type. We can see that result below in data storage. (Note that Number fields do not offer Minimal indexing. It is all or nothing.) Switching to number fields for UUIDNumber reduces the space requirements dramatically. An ID based on UUIDNumber now requires only slightly more space than the amount needed for UUID.

The question of size is relative for different settings. The data graphs we’ve seen so far are based on a data set of 21,300 records. For many users, that is a considerable number of records. Although for FileMaker databases, it is not a large number. So let’s look at a larger data set.
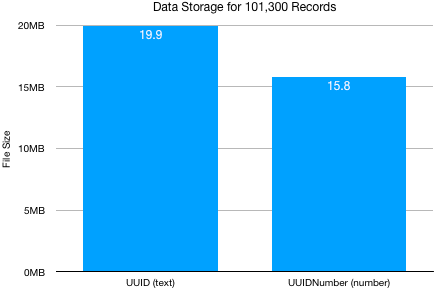
We decided to increase the number of records to 101,300 records. We created the optimal settings for ID fields, which is to have indexing turned on, and for text fields to be set to minimal indexing. Prior to running the experiment we were wondering whether the larger number of fields would modify the ratio of difference in storage requirements. In fact, that did happen but not in the way we thought it would.
When much larger data sets are tested, a number field storing UUIDNumber as an ID uses less space than UUIDs stored in a text field.


We saw that a properly configured UUIDNumber uses marginally more storage at smaller data sizes. In our experiment, at 21,300 records UUIDNumber was using 3.4MB of storage space when UUID was using 3MB. The difference in size at that point is only 400KB. That isn’t a big enough amount to be concerned about.
Using number fields for IDs is reported to produce faster results for related processes on large data sets. For that reason the extra storage overhead would be justified by the benefits in performance for the user. To our surprise, we discovered that at large numbers, the storage requirements of UUIDNumber is less than for UUIDs.
Our Method
For every iteration we created a new FileMaker database. The auto generated table was given a single field, named “id”. The field was set to be text or number and the index options were set. A script was added which automatically generated records. Within the relationship graph we duplicated the table and created a relationship between the table occurrences based on the ID field. This was done to ensure that indexes would be created for the tables. This is a necessary condition to emulate the way a database will behave in ordinary use.
Attachments
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Are UUIDs really unique? (Ludi Rehak) Towards Data Science. [↩]